
핵심 요약
- 사용자가 입력한 문자열과 모델에게 전달되는 message는 같지 않다.
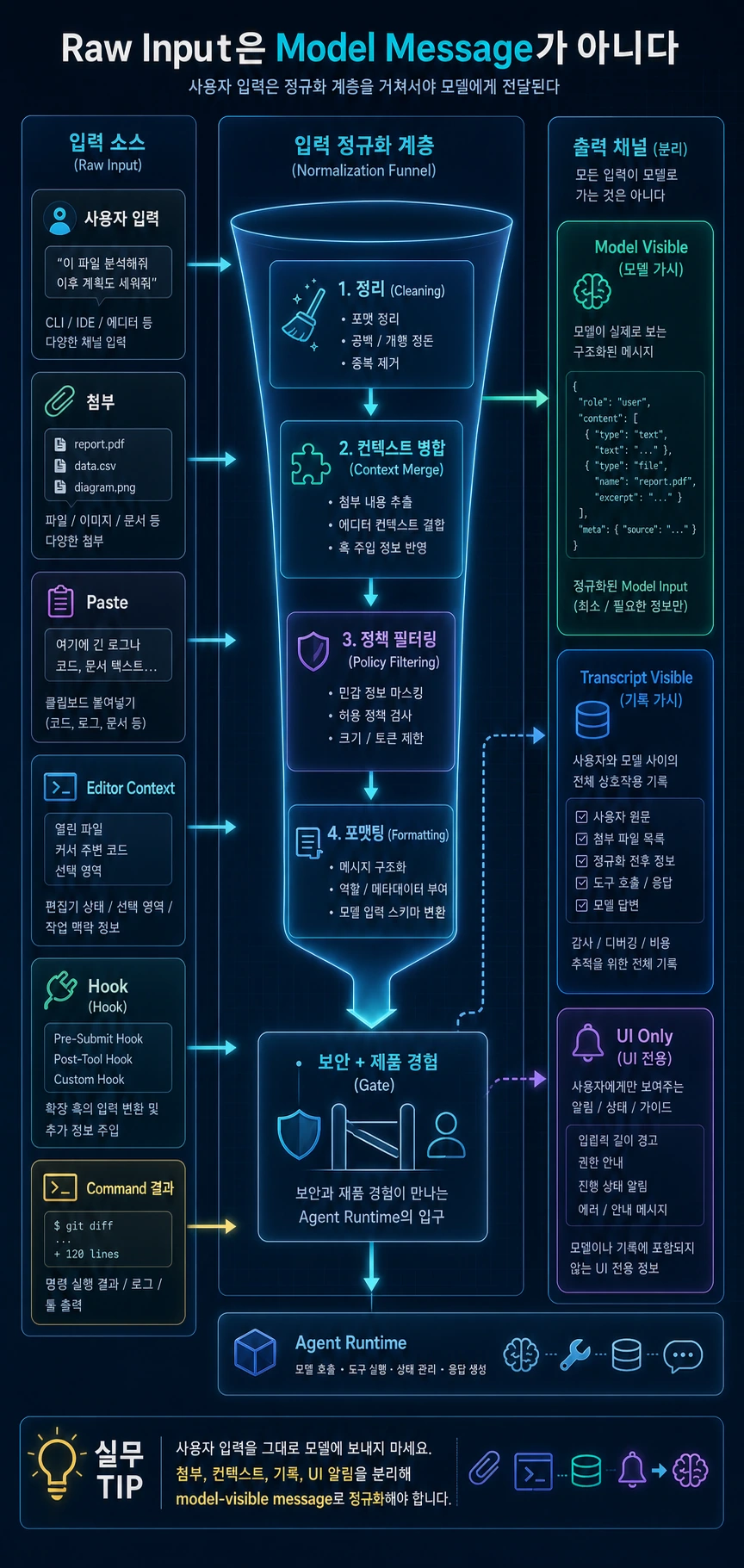
- 입력 정규화 계층은 attachment, paste, editor context, hook, command 결과를 처리한다.
- UI-only notice, transcript-visible event, model-visible content를 분리해야 한다.
- 이 계층은 보안과 제품 경험이 만나는 agent의 입구다.
이번 글에서는 agent runtime의 “입”을 다룹니다. 사용자가 입력한 raw text가 어떻게 model-visible message가 되는지입니다.
AI agent를 처음 만들 때는 사용자의 입력 문자열을 그대로 모델에 보내기 쉽습니다. 하지만 제품형 agent에서는 그렇게 하면 안 됩니다. 사용자의 입력 주변에는 첨부, 붙여넣은 긴 텍스트, 에디터 선택 영역, local command, hook 결과, 작업 디렉터리 정보, 경고 메시지 같은 context가 붙습니다.
이 모든 것을 다루는 계층이 input normalization입니다.
1. Raw input과 model message는 왜 다른가
사용자가 보는 입력은 문자열입니다.
# 읽는 법: 아래 항목은 동작 흐름을 빠르게 확인하기 위한 요약 예시입니다.이 파일 구조 보고 리팩터링 방향 제안해줘하지만 runtime이 모델에게 보내야 하는 message는 훨씬 더 복잡할 수 있습니다.
- 사용자가 첨부한 파일 요약
- 현재 에디터에서 선택한 코드 영역
- 작업 디렉터리 metadata
- command가 생성한 prompt template
- hook이 추가한 프로젝트 규칙
- 모델에게는 보이지 않아야 하는 UI 안내
따라서 입력 정규화는 단순 parser가 아닙니다. 어떤 정보가 모델에게 보여야 하고, 어떤 정보는 화면에만 남아야 하며, 어떤 정보는 기록에만 남겨야 하는지를 결정하는 보안 경계입니다.
2. 입력 정규화 계층의 책임
| 책임 | 설명 |
|---|---|
| surface text cleanup | 공백, 빈 입력, 특수 입력 정리 |
| command detection | 일반 prompt와 command 구분 |
| attachment conversion | 파일, 이미지, paste block을 content block으로 변환 |
| hook execution | 정책 검사, context 주입, 차단 결정 |
| message projection | model-visible message와 UI-only notice 분리 |
| call decision | 모델 호출 필요 여부 결정 |
정규화의 최종 결과는 문자열이 아니라 PreparedTurn 같은 구조가 되어야 합니다.
3. UI-only, model-visible, transcript-visible 구분
정규화 계층에서 가장 중요한 구분은 visibility입니다.
| 내용 | UI | 모델 | 기록 |
|---|---|---|---|
| 사용자 원본 질문 | 예 | 보통 예 | 예 |
| attachment 변환 결과 | 요약 예 | 예 | 예 |
| 비용 경고 | 예 | 아니오 | 예 |
| hook 차단 사유 | 예 | 경우에 따라 아니오 | 예 |
| command prompt template | 경우에 따라 예 | 예 | 예 |
| local command result | 예 | 경우에 따라 아니오 | 예 |
이 구분이 없으면 모델 context에 불필요한 UI 문구가 들어가거나, 반대로 모델에게 꼭 필요한 관찰값이 누락됩니다.
주의:
“화면에 보여준 것 = 모델에게 보낸 것”으로 설계하면 나중에 보안 문제가 생길 수 있습니다. 승인 UI 문구, 내부 경고, 비용 알림은 사용자에게 필요하지만 모델에게는 불필요하거나 위험할 수 있습니다.
4. Hook을 어디에 배치할 것인가
hook은 모델 호출 전에 실행되어야 합니다. 이유는 간단합니다. 모델에게 보내면 안 되는 입력은 보내기 전에 막아야 합니다.
hook은 다음 작업을 할 수 있습니다.
- 입력을 차단한다.
- 프로젝트 규칙을 추가한다.
- command를 확장한다.
- 민감 정보 포함 여부를 경고한다.
- 특정 도구 사용을 제한한다.
다만 hook도 side effect를 가질 수 있으므로 권한과 기록 대상이 되어야 합니다. 특히 프로젝트 내부 hook을 신뢰하기 전에 실행하면 안 됩니다.
5. Command 결과를 message로 맞추는 방법
command는 local action일 수도 있고, model prompt를 생성할 수도 있습니다. 중요한 것은 command system이 어떤 결과를 내든 정규화 계층의 반환 타입이 유지되어야 한다는 점입니다.
| command 종류 | 반환 예시 |
|---|---|
| local command | should_call_model=False, UI notice 포함 |
| prompt command | should_call_model=True, generated message 포함 |
| interactive command | overlay open event 포함 |
| restricted command | warning event, model 호출 없음 |
즉 downstream의 model loop는 “이게 command였는지”를 몰라도 됩니다. 준비된 message 묶음만 받으면 됩니다.
6. 개념 코드로 보는 normalization
아래 코드는 원본 구현과 무관한 설명용 코드입니다.
# 읽는 법: 실제 구현 복제가 아니라 runtime 경계를 설명하는 개념 코드입니다.class PreparedTurn: # 객체가 이후 단계에서 참조할 runtime 의존성과 상태 저장소를 초기화합니다. def __init__(self, turn_id, messages, should_call_model, visible_events=None, tool_filter=None): self.turn_id = turn_id self.messages = messages self.should_call_model = should_call_model self.visible_events = visible_events or [] self.tool_filter = tool_filter # 첨부, slash command, hook을 거쳐 raw 입력을 model-visible message로 바꿉니다.async def prepare_turn(draft, runtime): visible_events = [] content_blocks = [] for item in draft.attachments: converted = await runtime.attachment_reader.to_content_block(item) content_blocks.append(converted.model_block) visible_events.append(converted.screen_summary) command = runtime.commands.match(draft.text) if command is not None: command_result = await command.render(draft, runtime) return PreparedTurn( turn_id=draft.id, messages=command_result.messages, should_call_model=command_result.needs_model, visible_events=visible_events + command_result.visible_events, tool_filter=command_result.allowed_tools, ) user_message = build_user_message(draft.text, content_blocks) hook_result = await runtime.input_hooks.review(user_message, draft) if hook_result.blocked: return PreparedTurn( turn_id=draft.id, messages=[], should_call_model=False, visible_events=visible_events + [make_warning(hook_result.reason)], ) final_message = hook_result.apply_to(user_message) return PreparedTurn( turn_id=draft.id, messages=[final_message], should_call_model=True, visible_events=visible_events, tool_filter=hook_result.tool_filter, )여기서 중요한 점은 반환값에 should_call_model이 포함된다는 것입니다. 모든 입력이 모델 호출로 이어지는 것은 아닙니다.
7. AI 활용 개발자 관점
AI 도구를 사용할 때 다음을 관찰해보면 좋습니다.
- 첨부 파일을 넣었을 때 모델이 어떤 범위까지 읽는지 표시하는가?
- local command 결과가 모델 context에 들어가는지 구분되는가?
- 프로젝트 규칙이나 hook이 실행될 때 사용자에게 알려주는가?
- 민감 정보가 포함된 입력을 보내기 전에 경고하는가?
- command가 생성한 prompt가 사용자에게 보이는가?
이런 정보가 명확한 도구일수록 팀에서 안전하게 쓰기 쉽습니다.
8. Agent 개발자 체크리스트
# 읽는 법: 아래 항목은 동작 흐름을 빠르게 확인하기 위한 요약 예시입니다.Input Normalization 체크리스트 [ ] raw input과 model-visible message가 다른 타입으로 관리된다.[ ] attachment 변환 결과는 UI 요약과 model block으로 나뉜다.[ ] hook은 모델 호출 전에 실행된다.[ ] hook 차단 결과는 사용자에게 보이고 기록에도 남는다.[ ] command 결과는 PreparedTurn 같은 공통 반환 타입으로 맞춰진다.[ ] UI-only notice가 모델 context로 새지 않는다.[ ] 모델 호출 여부가 정규화 결과에 명시된다.마무리
입력 정규화는 agent의 품질과 안전성을 동시에 결정합니다. 사용자의 입력을 그대로 모델에 보내는 구조는 빠르게 만들 수 있지만, 첨부, hook, command, 권한, 기록이 붙는 순간 한계가 옵니다.
다음 글에서는 command system을 보겠습니다. Claude Code류의 slash command는 단순 단축키가 아니라 runtime dispatch 계층으로 이해해야 합니다.
독자 적용 노트
이 글은 AI agent나 코딩 도구를 실제 개발 업무에 적용하려는 개발자가 Raw Input을 Model Message로 바꾸는 입력 정규화 계층이라는 주제를 단순 개념 설명이 아니라 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계로 점검하도록 작성했습니다. 본문에서 다룬 구조는 새 도구를 도입하거나 기존 워크플로우를 바꿀 때 "무엇을 먼저 확인해야 하는가"를 정하는 데 쓰는 것이 좋습니다.
원본 판단 근거
이 글의 판단은 1. Raw input과 model message는 왜 다른가에서 설명한 구조와 본문 안의 예시, 표, 체크리스트를 함께 놓고 정리한 것입니다. 특히 독자가 그대로 복사할 수 있는 결론보다, 자신의 코드베이스나 팀 규칙에 맞춰 확인해야 할 경계와 실패 조건을 분리하는 데 초점을 둡니다.
실패 사례 또는 edge case
가장 흔한 실패는 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계를 문서나 명칭만 맞춘 상태로 끝내는 것입니다. 예를 들어 실제 입력, 권한, 로그, 배포, 검증 기준이 연결되지 않으면 겉으로는 도입이 끝난 것처럼 보여도 다음 작업에서 같은 문제가 반복됩니다. 따라서 본문을 적용할 때는 "누가 실행하는가", "무엇을 기록하는가", "실패하면 어디서 멈추는가"를 같이 확인해야 합니다.
실무 체크리스트
- 이 글의 핵심 개념을 현재 프로젝트의 실제 파일, API, 로그, 문서 중 하나에 연결했다.
- 본문 예시를 그대로 쓰지 않고 우리 환경의 제약 조건으로 다시 검토했다.
- 실패 사례나 edge case를 하나 이상 정하고, 재현 또는 확인 방법을 적었다.
- 적용 후 바뀌어야 할 완료 기준과 검증 명령을 분리했다.
Q&A
Q1. 이 글의 내용을 바로 표준으로 써도 되나요?
바로 표준으로 고정하기보다 작은 작업 하나에 먼저 적용해 보는 편이 안전합니다. 실제 로그, 리뷰, 테스트에서 같은 판단이 반복해서 맞을 때 팀 표준으로 올리는 것이 좋습니다.
Q2. 본문 예시와 내 프로젝트가 다르면 어떻게 해야 하나요?
예시의 이름보다 경계를 보세요. 입력, 상태, 권한, 검증, 기록 중 어떤 경계를 다루는 글인지 먼저 찾고, 그 경계를 현재 프로젝트의 구조에 맞게 옮기면 됩니다.
참고자료와 불확실성
이 보강 노트는 본문에 이미 포함된 참고자료와 작성 시점의 공개 문서를 기준으로 합니다. 도구 버전, API 정책, 제품 UI는 바뀔 수 있으므로 실제 적용 전에는 공식 문서와 현재 런타임 동작을 다시 확인해야 합니다.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.