
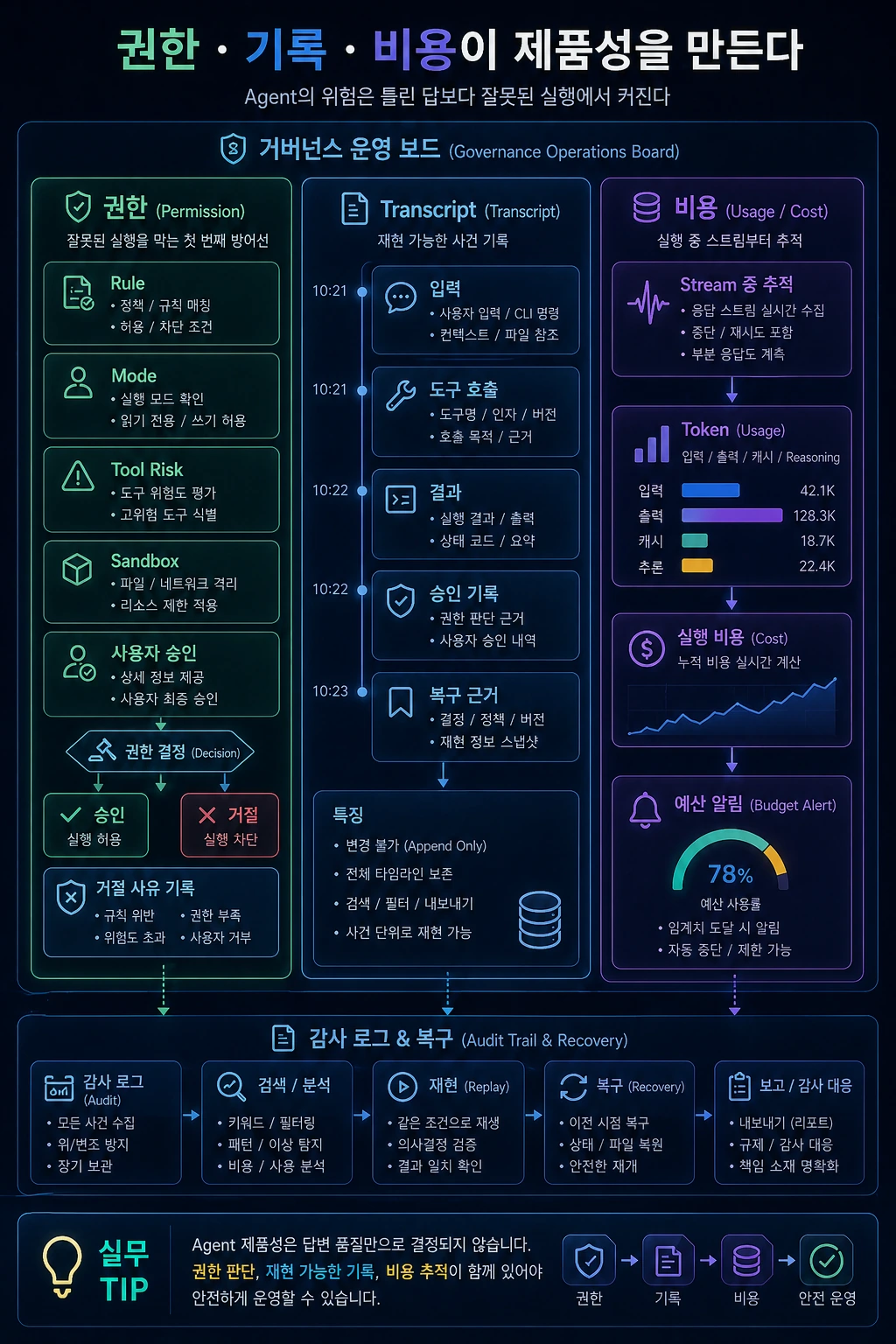
핵심 요약
- Agent의 위험은 틀린 답보다 잘못된 실행에서 커진다.
- Permission gate는 단일 if 문이 아니라 rule, mode, tool risk, sandbox, user approval을 보는 계층이다.
- Transcript는 채팅 로그가 아니라 재현 가능한 사건 기록이다.
- Usage와 cost는 장기 실행 agent에서 stream 중간부터 추적되어야 한다.
마지막 글에서는 agent 제품성의 마지막 방어선을 다룹니다. 권한, transcript, 비용입니다.
AI agent의 위험은 모델이 틀린 답을 하는 데서만 오지 않습니다. 더 큰 위험은 모델이 사용자의 파일을 바꾸거나, shell 명령을 실행하거나, 외부 시스템에 데이터를 보낼 때 발생합니다. 그래서 permission, transcript, cost accounting은 나중에 붙이는 부가기능이 아니라 runtime의 핵심입니다.
Claude Code류의 agent를 분석 관점으로 보면 이 셋은 같은 사건을 서로 다른 방식으로 봅니다. 도구 요청이 들어오면 permission gate가 판단하고, ledger는 그 결정을 기록하고, accounting은 모델과 도구 사용량을 추적합니다.
1. 권한은 왜 마지막 방어선인가
모델은 의도를 추론하지만, 실행의 책임은 runtime에 있습니다. 모델이 “이 파일을 수정하자”고 말할 수는 있지만, 실제 파일 쓰기를 허용할지는 runtime이 결정해야 합니다.
권한 설계가 약하면 다음 문제가 생깁니다.
- 사용자가 승인하지 않은 파일 수정
- 위험한 shell 명령 실행
- 비밀키나 환경변수 노출
- 외부 네트워크로 민감 데이터 전송
- 어떤 작업이 왜 실행됐는지 설명 불가
보안 주의:
AI agent를 회사 코드베이스에 적용하기 전에는 권한 모드, 로그 보관 범위, 데이터 전송 범위, 비밀 정보 마스킹, rollback 절차를 반드시 확인해야 합니다.
2. Layered permission 설계
좋은 permission gate는 단일 boolean check가 아닙니다. 여러 계층을 순서대로 봅니다.
| 순서 | 계층 | 설명 |
|---|---|---|
| 1 | explicit deny | 명시적으로 금지된 작업 차단 |
| 2 | policy rule | 조직/프로젝트/사용자 규칙 적용 |
| 3 | tool risk | 도구의 위험도 확인 |
| 4 | argument risk | 입력값 자체의 위험 판단 |
| 5 | sandbox mode | 격리 실행 가능 여부 확인 |
| 6 | auto-allow | 안전 조건에서만 자동 허용 |
| 7 | interactive approval | 사용자에게 질문 |
| 8 | decision record | 결정과 이유 기록 |
중요한 것은 자동 허용이 안전 검사보다 뒤에 와야 한다는 점입니다. 자동화는 편의 기능이지 안전장치 해제가 아닙니다.
3. 승인 UI와 결정 기록
사용자에게 묻는 것은 permission gate의 일부지만, UI와 정책 판단은 분리해야 합니다.
정책 엔진은 다음 중 하나를 반환합니다.
- 허용
- 거부
- 사용자 확인 필요
UI는 “사용자 확인 필요”를 사람이 이해할 수 있는 dialog로 바꿉니다. 그리고 사용자의 선택은 ledger에 남아야 합니다.
| 기록 항목 | 이유 |
|---|---|
| capability name | 어떤 도구인지 식별 |
| argument summary | 무엇을 하려 했는지 설명 |
| decision | 허용/거부/항상 허용 |
| reason | 정책, 사용자 선택, 위험도 |
| approver | 사람이 승인했는지 자동 승인인지 |
| turn id | 어떤 agent turn에 속하는지 연결 |
4. Transcript를 채팅 로그로 보면 안 되는 이유
transcript는 “대화 내용 저장”이 아닙니다. agent 실행을 재현하기 위한 사건 기록입니다.
좋은 transcript는 다음 질문에 답할 수 있어야 합니다.
- 사용자가 어떤 입력을 보냈는가?
- 모델은 어떤 도구를 요청했는가?
- runtime은 어떤 권한 결정을 내렸는가?
- 사용자는 무엇을 승인했는가?
- 도구 결과는 무엇이었는가?
- 그 결과를 보고 모델은 어떤 다음 판단을 했는가?
- 비용과 토큰은 어느 시점에 증가했는가?
이 질문에 답하지 못하면 디버깅, 감사, 복구가 어렵습니다.
5. Usage와 cost accounting
장기 실행 agent는 여러 번 모델을 호출하고, 도구 결과를 다시 넣고, context를 압축하고, retry를 수행할 수 있습니다. 비용을 마지막에 한 번 계산하면 오차가 커집니다.
따라서 usage와 cost는 stream event 단계에서 누적해야 합니다.
| 이벤트 | accounting 처리 |
|---|---|
| model request start | 요청 metadata 기록 |
| usage update | token/cache/reasoning 사용량 병합 |
| tool execution | tool call count, 외부 API 비용 기록 |
| retry/fallback | 별도 request로 연결 |
| cancel | 현재까지 사용량 확정 |
| final | turn summary 생성 |
6. 개념 코드로 보는 안전 계층
아래 코드는 설명용으로 새로 작성한 코드입니다.
# 읽는 법: 실제 구현 복제가 아니라 runtime 경계를 설명하는 개념 코드입니다.class PermissionDecision: # 객체가 이후 단계에서 참조할 runtime 의존성과 상태 저장소를 초기화합니다. def __init__(self, allowed, reason, requires_user=False): self.allowed = allowed self.reason = reason self.requires_user = requires_user # 정책, 위험도, 자동 허용 조건, 사용자 승인 순서로 실행 가능 여부를 결정합니다.async def evaluate_permission(tool, args, runtime): if runtime.policy.denies(tool, args): return PermissionDecision(False, "explicit_deny") risk = classify_risk(tool, args, runtime.workspace) if risk.level == "blocked": return PermissionDecision(False, risk.reason) if runtime.policy.auto_allows(tool, args, risk): return PermissionDecision(True, "auto_allow") user_choice = await runtime.shell.ask_approval( title=f"{tool.name} 실행 승인", body=build_risk_explanation(tool, args, risk), ) if user_choice == "deny": return PermissionDecision(False, "user_denied") return PermissionDecision(True, f"user_{user_choice}") # 권한 결정을 ledger에 남긴 뒤 허용된 도구만 실제 실행합니다.async def guarded_tool_execution(request, runtime): decision = await evaluate_permission(request.tool, request.args, runtime) await runtime.ledger.write("permission", { "tool": request.tool.name, "decision": decision.allowed, "reason": decision.reason, "turn": runtime.current_turn_id, }) if not decision.allowed: return ToolResult.denied(request.id, decision.reason) result = await runtime.tools.execute_without_rechecking(request) await runtime.ledger.write("tool_result", result.audit_summary()) return result권한 판단과 기록은 분리되어 있지만 같은 사건을 공유합니다. 이렇게 해야 나중에 “왜 실행됐는가”를 설명할 수 있습니다.
7. AI 활용 개발자 관점
AI 도구를 쓰는 개발자는 다음을 확인해야 합니다.
| 질문 | 이유 |
|---|---|
| 파일 쓰기 전에 승인을 요구하는가? | 원치 않는 변경 방지 |
| shell 명령을 보여주고 실행하는가? | 위험 명령 확인 |
| 항상 허용 규칙을 관리할 수 있는가? | 과도한 자동화 방지 |
| transcript를 확인할 수 있는가? | 감사와 디버깅 |
| 비용/토큰 사용량을 볼 수 있는가? | 예산 관리 |
| 실패 후 rollback이 쉬운가? | 실무 안정성 |
팀에서 도입한다면 이 질문들이 곧 도입 기준이 됩니다.
8. Agent 개발자 체크리스트
# 읽는 법: 아래 항목은 동작 흐름을 빠르게 확인하기 위한 요약 예시입니다.Permission / Transcript / Cost 체크리스트 [ ] 권한 판단은 단일 if가 아니라 layered gate로 설계되어 있다.[ ] explicit deny와 민감 작업 검사는 auto-allow보다 먼저 실행된다.[ ] 승인 UI와 정책 엔진이 분리되어 있다.[ ] 권한 거절도 model-visible tool result로 돌아간다.[ ] transcript는 사용자 입력, 모델 응답, tool request, permission decision, result를 연결한다.[ ] usage/cost는 stream 중간에도 갱신된다.[ ] cancel/retry/fallback 상황에서도 accounting이 유지된다.[ ] session restore 시 transcript와 cost state가 함께 복원된다.9. 마무리 Q&A
Q1. 권한을 너무 자주 물으면 사용성이 나빠지지 않나?
맞습니다. 그래서 layered permission이 필요합니다. 안전한 read-only 작업은 자동 허용할 수 있고, 위험한 write/shell/network 작업은 승인하도록 나눠야 합니다.
Q2. transcript는 모든 내용을 그대로 저장해야 하나?
아닙니다. 민감 정보는 마스킹하거나 요약해야 합니다. 중요한 것은 원본을 무조건 저장하는 것이 아니라 사건 순서와 결정 이유를 복구 가능하게 남기는 것입니다.
Q3. 비용 추적은 MVP에서 빼도 되나?
개인 데모라면 가능하지만, 장기 실행 agent나 팀 도입을 생각한다면 초기에 최소한의 usage snapshot은 넣는 편이 좋습니다. 나중에 붙이면 request, retry, cancellation의 연결을 복원하기 어렵습니다.
최종 정리
Claude Code류의 agent를 runtime 관점으로 분석하면 마지막에 남는 질문은 하나입니다.
이 agent는 자동화할 수 있는가보다, 안전하게 자동화할 수 있는가?
권한, transcript, 비용은 이 질문에 답하기 위한 핵심 계층입니다. 이 셋이 없으면 agent는 빠를 수는 있지만 신뢰하기 어렵습니다. 반대로 이 셋을 처음부터 설계하면 작은 agent도 제품 수준으로 성장할 수 있습니다.
독자 적용 노트
이 글은 AI agent나 코딩 도구를 실제 개발 업무에 적용하려는 개발자가 권한, Transcript, 비용이 Agent 제품성을 결정한다이라는 주제를 단순 개념 설명이 아니라 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계로 점검하도록 작성했습니다. 본문에서 다룬 구조는 새 도구를 도입하거나 기존 워크플로우를 바꿀 때 "무엇을 먼저 확인해야 하는가"를 정하는 데 쓰는 것이 좋습니다.
원본 판단 근거
이 글의 판단은 1. 권한은 왜 마지막 방어선인가에서 설명한 구조와 본문 안의 예시, 표, 체크리스트를 함께 놓고 정리한 것입니다. 특히 독자가 그대로 복사할 수 있는 결론보다, 자신의 코드베이스나 팀 규칙에 맞춰 확인해야 할 경계와 실패 조건을 분리하는 데 초점을 둡니다.
실패 사례 또는 edge case
가장 흔한 실패는 AI 도구를 실제 작업 흐름에 붙일 때의 실행 경계를 문서나 명칭만 맞춘 상태로 끝내는 것입니다. 예를 들어 실제 입력, 권한, 로그, 배포, 검증 기준이 연결되지 않으면 겉으로는 도입이 끝난 것처럼 보여도 다음 작업에서 같은 문제가 반복됩니다. 따라서 본문을 적용할 때는 "누가 실행하는가", "무엇을 기록하는가", "실패하면 어디서 멈추는가"를 같이 확인해야 합니다.
실무 체크리스트
- 이 글의 핵심 개념을 현재 프로젝트의 실제 파일, API, 로그, 문서 중 하나에 연결했다.
- 본문 예시를 그대로 쓰지 않고 우리 환경의 제약 조건으로 다시 검토했다.
- 실패 사례나 edge case를 하나 이상 정하고, 재현 또는 확인 방법을 적었다.
- 적용 후 바뀌어야 할 완료 기준과 검증 명령을 분리했다.
Q&A
Q1. 이 글의 내용을 바로 표준으로 써도 되나요?
바로 표준으로 고정하기보다 작은 작업 하나에 먼저 적용해 보는 편이 안전합니다. 실제 로그, 리뷰, 테스트에서 같은 판단이 반복해서 맞을 때 팀 표준으로 올리는 것이 좋습니다.
Q2. 본문 예시와 내 프로젝트가 다르면 어떻게 해야 하나요?
예시의 이름보다 경계를 보세요. 입력, 상태, 권한, 검증, 기록 중 어떤 경계를 다루는 글인지 먼저 찾고, 그 경계를 현재 프로젝트의 구조에 맞게 옮기면 됩니다.
참고자료와 불확실성
이 보강 노트는 본문에 이미 포함된 참고자료와 작성 시점의 공개 문서를 기준으로 합니다. 도구 버전, API 정책, 제품 UI는 바뀔 수 있으므로 실제 적용 전에는 공식 문서와 현재 런타임 동작을 다시 확인해야 합니다.
댓글
GitHub 계정으로 로그인하면 댓글을 남길 수 있습니다. 댓글은 GitHub Discussions를 통해 운영됩니다.